切片集群:数据量大怎么办
本文内容
1. 纵向扩展 vs 横向扩展
当 Redis 需要保存大量数据时,一般都有两种方案,纵向扩展(scale up)和横向扩展(scale out):
- 纵向扩展:升级单个实例的配置,比如增加内存容量、CPU 核数和磁盘容量等;
- 横向扩展:增加实例的个数,比如从 1 台实例增加到 3 态。

这两种方式各有什么优缺点呢?
纵向扩展 一个很明显的好处就是 实施起来简单、直接,因为只需要使用更高规格的服务器即可,不需要关注其他。
但也有两个缺点:
- 当使用 RDB 快照 进行持久化时,如果一台实例上的数据量过大,内存使用过多,主线程在 fork 子进程时可能会造成阻塞,因为内存太大会导致 拷贝页表时耗时较长。同理,若使用 AOF 日志,AOF 重写时也会造成阻塞;
- 硬件和成本有所限制,比如把内存从 32GB 扩展到 64GB 还算容易,但要扩展到几百 GB,甚至 1 TB,就很难找到这么大容量的内存了,而且价格成本也会大大增加。
而横向扩展就可以很好的避免上面纵向扩展的问题,因为只需要增加实例个数即可,实例的内存小点也没关系。在百万、千万级用户规模时,横向扩展是一个很好的选择。
2. Redis 切片集群 — Cluster 方案
在 Redis 中,提供了 切片集群 来支持横向扩展,切片集群是由多个 Redis 实例组成的集群,会按照一定规则把数据划分到多个实例中。
不过对于切片集群,需要考虑一个复杂的问题,就是数据存在哪个切片上,这个映射规则是什么?客户端怎么访问实例?
这些都是 Redis 切片集群需要解决的问题,而 Redis 3.0 开始,提供了一个名为 Redis Cluster 的方案,用来实现切片集群,解决了上面的问题。
2.1 数据和实例的映射关系
在切片集群中,数据是分布到不同的实例上的,首先要解决的就是数据和实例之间如何映射?在 Redis Cluster 方案中规定了数据和实例的对应规则。
Redis Cluster 采用 哈希槽 Hash Slot 来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群有 16384 个哈希槽,每个键值对会根据 key 被映射到一个哈希槽中,这个映射过程分为两步:
- 根据 key 按照 CRC16 算法计算出一个 16 bit 的值;
- 用该 16 bit 值对 16384 取模,得到一个 0~16384 内的模数,每个模数代表一个哈希槽。
key 映射到哈希槽后,这些哈希槽又会被映射到具体的 Redis 实例上,下面来看看哈希槽到实例的映射规则。
在部署 Redis Cluster 方案时,可以使用 cluster create 命令创建集群,此时 Redis 会 把 16384 个哈希槽平均分配在集群中。例如有 N 个实例的集群,那每个实例上会有 16384/N 个哈希槽。
除了平均分配外,也可以使用 cluster meet 命令手动建立实例间的连接,形成集群,然后使用 cluster addslots 命令指定每个实例上的哈希槽个数。想要根据 Redis 服务器不同配置,分配不同数量的哈希槽时,可以使用该手动分配方法。
不过需要注意,在手动分配哈希槽时,要把 16384 个哈希槽都分配完,否则 Redis 集群无法正常工作。
到此,通过哈希槽完成了数据和实例的映射,数据、哈希槽、实例这三者的映射 就像下面这样:
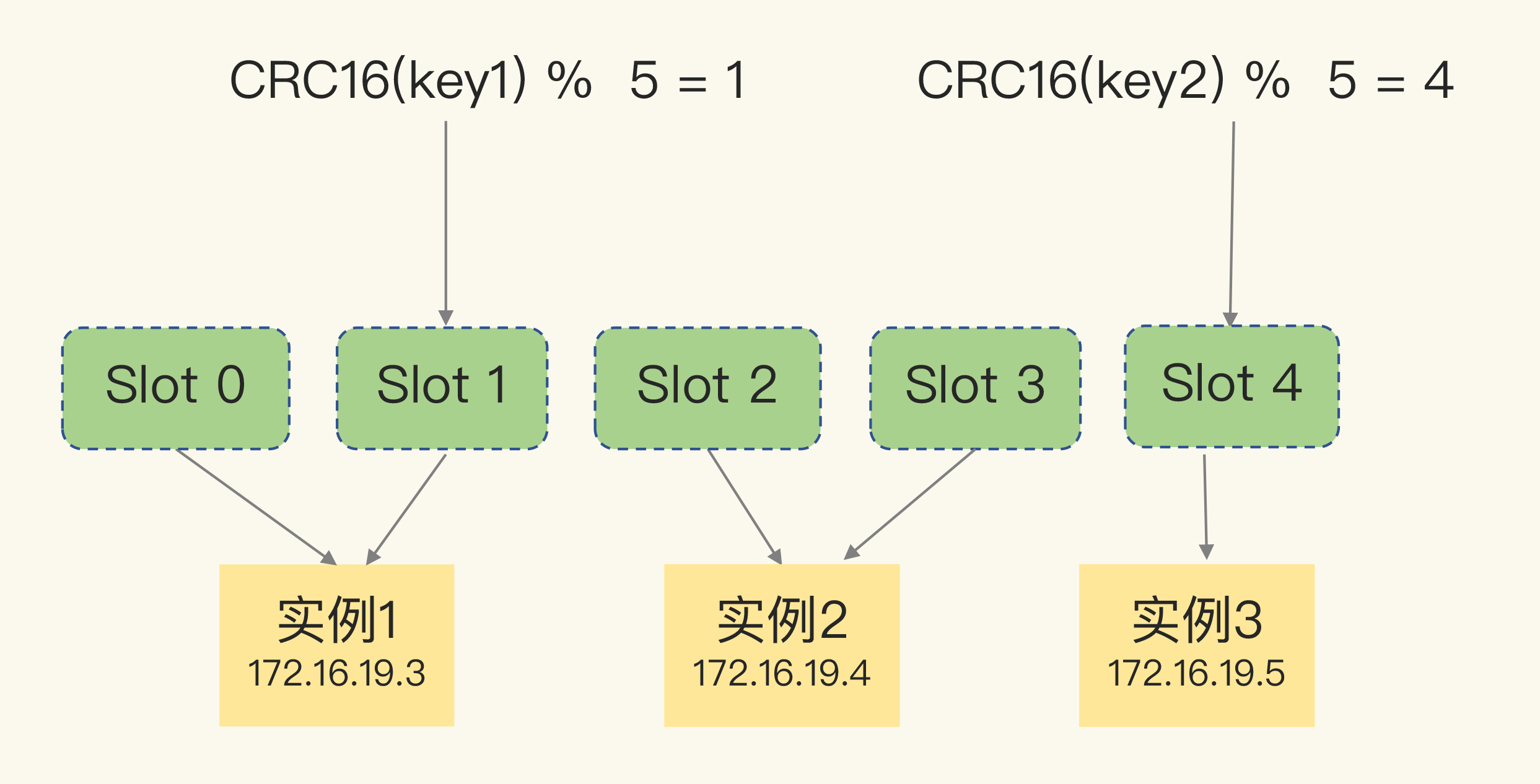
2.2 客户端访问实例
有了数据和实例的映射关系后,还需要解决 客户端如何知道要访问的数据在哪个实例上?
首先来看看键值对到实例的映射路径:键值对的 key -> 哈希槽位 -> 实例。
客户端本身可以在发送请求时通过 CRC16 算法对 key 进行计算,再对 16384 取模,得到哈希槽位,但是 客户端如何知道该哈希槽分布在哪个实例上呢?
客户端在和集群实例建立连接后,Redis 实例就会把哈希槽的分配信息发送给客户端,但是,每个实例只知道自己身上的哈希槽,不知道其他实例的,那客户端怎么 在访问任何一个实例时,就能获取到所有的哈希槽信息呢?
其实,Redis 实例之间会互相共享哈希槽的分配信息,当实例之间互相连接后,每个实例就都有所有哈希槽的映射关系了。
客户端收到哈希槽信息后,就会把哈希槽信息缓存在本地,客户端请求时,先计算出 key 的哈希槽后,就可以向对应的实例发送请求了。
不过 哈希槽和实例的映射不是一成不变的,比如:
- 集群实例数量的扩容或缩容,都会导致哈希槽的重新分配;
- 为了 将数据负载均衡,需要把哈希槽重新分配一遍。
此时 集群实例之间还可以通过互相传递信息获取最新的哈希槽分配信息,但 客户端是无法主动感知这些变化的,如果还按照本地缓存的信息去请求,怎么请求得到数据呢?
Redis Cluster 方案提供了一种 重定向机制,客户端在向一个实例发送请求时,如果该实例上没有该数据对应的哈希槽,就会响应下面的 MOVED 命令,其中包含了新实例的访问地址:
GET hello:key
(error) MOVED 13320 172.16.19.5:6379
该 MOVED 命令表示客户端请求的键值对所在的哈希槽 13320 实际在 172.16.19.5 实例上。
通过这个 MOVED 命令,就相当于把该哈希槽所在的新实例的信息告诉了客户端,客户端知道后就会更新本地缓存。
例如,由于负载均衡,Slot 2 从实例 2 迁移到了实例 3,客户端请求的逻辑如下:

注意,如果 Slot 2 中的数据比较多,可能会出现数据一部分迁移到了实例 3 上,还有一部分任然在实例 2 中的情况。在这种 迁移部分完成 的情况下,客户端会收到一条 ASK 信息,如下所示:
GET hello:key
(error) ASK 13320 172.16.19.5:6379
该 ASK 命令表示,客户端请求的键值对所在的哈希槽 13320 在 172.16.19.5 实例上,但是 该哈希槽正在迁移。
此时客户端需要 先给 172.16.19.5 实例发送 ASKING 命令,表示 该实例允许执行客户端接下来发送的命令。然后客户端 再向该实例发送 GET 命令,才能读取到数据。
例如,Slot 2 正在从实例 2 迁移到实例 3,key1、key2 已经迁移过去,key3、key4 还在实例 2 中。此时客户端向实例 2 请求 key2 时,就会收到 ASK 命令,然后客户端可以先发送 ASKING 命令,再发送 get key2 命令获取数据:

注意:和 MOVED 命令不同,ASK 命令不会更新客户端的本地缓存。
3. 为什么不直接把 key 映射到实例,而要采用哈希槽?
Redis Cluster 方案 通过哈希槽把键值对分配到不同的实例上,这个过程需要对键值对的 key 做 CRC16 计算,然后再和哈希槽做映射。而如果 用一个映射表直接把键值对和实例的对应关系记录下来(例如键值对 1 在实例 2 上,键值对 2 在实例 1 上),这样就只用查表即可,Redis 为什么不这么做呢?
这是因为,当数据量非常多时,该映射表会非常庞大,无论该映射表存储在客户端还是服务端,都会 占用大量的内存空间。
而且通过上面的内容也知道,Redis Cluster 方案会 将映射信息共享到所有的实例上,以达到在数据迁移后的重定向的功能,所以每个实例上都有完整的路由信息。如果采用映射表,该映射表非常庞大时,实例间需要交换路由表信息就会消耗更多的网络资源,而且实例存储的路由表也会占用更多的内存。
采用哈希槽的方式,无论数据量多大,哈希槽的数量都是固定的 16384 个,所以实例只需要存储这么多个槽位信息,占用的内存不是很大。
在集群扩容、缩容、负载均衡时,实例中的数据会发生迁移,如果直接把 key 映射到实例,那会涉及到大量 key 映射关系的修改,维护成本太高。
因此,综合考虑,使用哈希槽是一个更合适的选择。
4. 参考文章
- 《Redis 核心技术与实战》