Redis 底层数据结构
本文内容
前言
Redis 之所以快,除了它是基于内存的数据库外,还有一个重要的因素,就是它底层的 数据结构。
所以,想知道 Redis 为什么快的秘诀之一,就是去探究探究它底层的数据结构。
> 前置知识:redisObject
Redis 使用 redisObject 结构体表示各种数据结构(Redis 种把各种数据类型看成不同的对象),redisObject 结构体中的属性如下:
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 指向 type 类型底层实现(数据结构)的指针
void *ptr;
} robj;
接下来分别简单的介绍一下这三个属性。
类型(type)
type 属性记录了对象(数据结构)的类型,即 String、List、Hash、Set、zSet。
在 Redis 种,key 总是 String 类型,而 value 可以是任意一种对象。
我们也可以使用 TYPE key 命令来查看该 key 对应 value 的类型。
编码(encoding)和 底层实现的指针(ptr)
encoding 属性记录了对象的编码,也就是 这个对象使用了什么数据结构作为底层实现,而 ptr 指针则指向了这个底层的数据结构。
Redis 中每种对象都至少使用了 2 种不同的编码,如下图列出了每种类型的对象可以使用的编码:

Redis 为对象提供至少 2 种不同的编码,Redis 为什么要这么做呢?
不同的编码对应着不同的底层数据结构,这就意味着可以 根据不同的场景来选择不同的数据结构,从而达到更加高效的数据存取,因为每种数据结构都有各自的优势与劣势。当你学习完这些数据结构后,就知道它们各自的使用场景了。
1. Redis 数据结构有哪些
Redis 中的 数据结构 不是指 String、List、Hash、Set、zSet 等这些基本数据类型,而是指这些 数据类型的底层实现。
下面通过一张数据类型和数据结构的对应关系图,了解一下五种基本数据类型的底层实现:
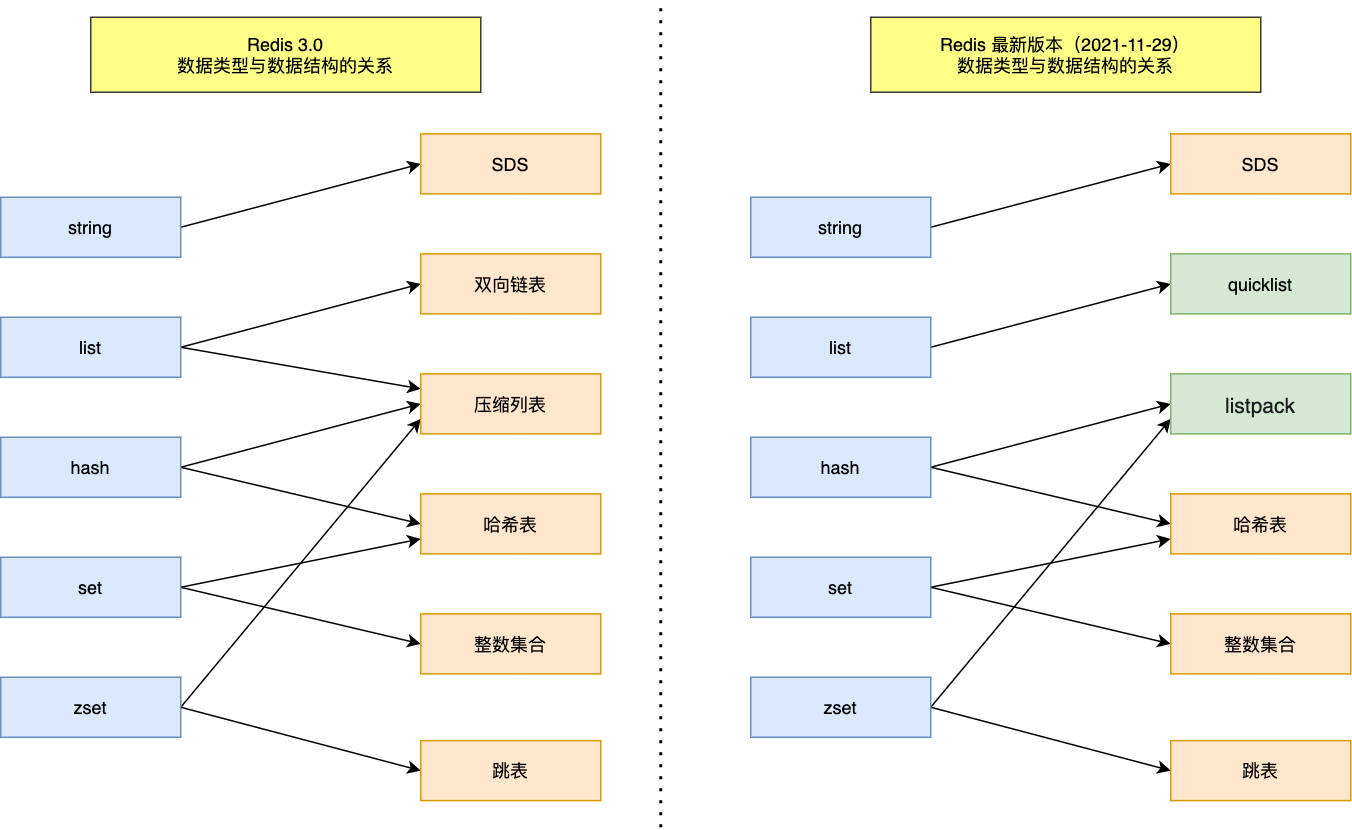
可以看见,之前的双向链表和压缩列表分别被 quicklist 和 listpack 代替了,至于为什么要做这个改变,看下去你就知道了。
2. 简单动态字符串 SDS
Redis 是用 C 语言实现的,但是它并没有直接使用 C 语言的 char* 字符数组来作为 Redis 字符串的底层实现,而是自己构建了一种 简单动态字符串(Simple Dynamic String,SDS)。
Redis 这么追求高效,不使用 C 语句的字符串肯定是它有一些缺陷,所以得先了解它有什么缺陷,才能知道 Redis 的 SDS 为什么要这么设计。下面就来对比下 C 字符串和 SDS 的设计:
1、C 字符串是以空字符('\0')结尾的字符数组,而 SDS 使用一个 len 属性来判断字符是否结束。
这就使得 C 字符串在获取长度时,需要额外计算,复杂度为 O(n),而 SDS 获取字符串长度的复杂度为 O(1)。
而且若字符串本身包含空字符时,会导致数据意外截断而发生错误,因此不能用于存储二进制数据,而 SDS 会以处理二进制的方式来处理数据,因此 可以保存二进制数据,例如图片、视频等文件。
2、C 字符串需要手动分配内存,而且分配后不可变,而 SDS 可以动态调整内存大小。
这就导致在拼接字符串,或者错误处理长度信息时,C 字符串可能会导致缓冲区溢出,进而导致内存越界访问,而 SDS 在拼接字符串之前,会 先检查内存空间 是否足够,不够会自动扩容,防止缓冲区溢出的问题。
2.1 SDS 结构
那么 SDS 是如何知道内存空间是否足够的呢?一个 SDS 结构有如下属性:
len:字符串长度,获取字符串长度时,返回该属性值即可;
alloc:分配的空间大小,检查内存空间是否足够时,使用 alloc - len 即可计算出剩余空间大小;
flags:SDS 的类型,分别有 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64 五种类型。影响的是 len 和 alloc 两个属性的类型,比如 sdshdr16 的 len 和 alloc 都是 uint16 类型,而 sdshdr32 则是 uint32 类型。这样可以使得在保存较小的字符串时,头结构使用的空间也比较小,而不是都使用一个较大类型的属性来表示。
buf[]:保存实际数据的字符数组,可以保存字符串和二进制数据。
由于 SDS 需要一些额外的空间来保存这些额外的信息,所以为了节省空间,Redis 还为 String 数据类型提供了多种不同的编码方式,分别是 int、row、embstr。只有在编码方式是 row 和 embstr 时,底层才使用了 SDS,这在 Redis 数据类型中会详细讲解。
2.2 内存对齐优化
除了上面为不同类型的 SDS 设置不同的结构体外,Redis 还 通过编译优化来避免内存对齐带来的空间消耗。
先来看看什么是内存对齐,当一个结构体中有两个类型不同的成员变量时,而且它们所占用的空间也不一样,那么编译器会按照 2 字节对齐的方式 给这些变量分配内存。
比如,下面这个结构体:
struct test1 {
char a;
int b;
} test1;
我们知道,在 C 语言中,char 类型占 1B,int 类型占 4B,那么该结构体应该占 5B。但实际上,它占用了 8B,这是因为即使 char 只占 1B,但由于编译器以 字节对齐 的方式分配内存(假设 CPU 一次读取 4 字节,编译器对齐系数为 4),所以也会为 char 分配 4B,来达到让 int 内存对齐的效果(让 int 变量起始地址为对齐系数的最小倍数)。
那么怎么取消内存对齐呢?只需要在声明结构体时,加上 __attribute__((packed)) 即可:
struct __attribute__((packed)) test2 {
char a;
int b;
} test2;
此时该结构体占用的字节数就是 5B 了,而 Redis 中的数据结构使用的正是这种定义方式,减少了内存对齐带来的空间消耗。
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
// ......
内存对齐有什么好处?
内存中存放的数据是给 CPU 使用的,CPU 一次能从内存中拿多少数据,受到 地址总线宽度 的限制,而且 CPU 从内存中获取数据时,起始地址必须是地址总线宽度的倍数。
例如 CPU 的地址总线是 64 位(8 字节),那么当一个 int 变量(4 字节)存储到 0x06 地址时,CPU 需要读取两次,才能获取这个变量的值:
- 第一次读取 0x00 ~ 0x08 这 8 个字节;
- 第二次读取 0x08 ~ 0x0F 这 8 个字节。
然后分别保存后两个字节和前两个字节,才能读取到这个变量的值。这样大大降低了 CPU 的执行效率。
内存对齐的目的就是为了让 CPU 一次能获取到数据,从而提升性能,而内存对齐,指的是 变量地址的对齐,即:变量起始地址 % 对齐系数 = 0,而 不是变量大小的对齐。回顾上面的结构体,就能明白了,把 int 变量内存地址对齐后,CPU 访问时,就可以一次获取到该变量。
每个平台的编译器都会有默认对齐系数(也叫对齐模数),可以通过预编译命令#pragma pack(n),n=1,2,4,8,16 来改变这一系数,一般默认为 8。
Redis 取消内存对齐会降低 CPU 性能吗?
Redis SDS 采用了 __attribute__ ((__packed__))(紧凑排列)取消了内存对齐,节省了内存,那么会不会对 CPU 访问产生影响呢?
我们观察一个细节,Redis 的不同 SDS 结构体声明,其 变量声明顺序都是按占用空间大小从大到小排列的,这样使得就算采用内存对齐,那也只对最后的变量起作用(尾随填充),而后面其实无需填充,CPU 一次性就能读取到所有数据(后面占用的空间小),所以就算 采用紧凑排列,也不会降低 CPU 的性能,还可以节约后面的内存。
3. 双向链表
Redis 的双向链表相比普通的双向链表,又封装了一层,使得操作更方便,list 结构定义如下:
typedef struct list {
listNode *head; //链表头节点
listNode *tail; //链表尾节点
void *(*dup)(void *ptr); //节点值复制函数
void (*free)(void *ptr); //节点值释放函数
int (*match)(void *ptr, void *key); //节点值比较函数
unsigned long len; //链表节点数量
} list;
listNode 结构就是普通的双向链表了:
typedef struct listNode {
struct listNode *prev; //前置节点
struct listNode *next; //后置节点
void *value; //节点的值
} listNode;

可以看出,Redis 的双向链表可以 很方便的获取头尾节点、节点数量,复杂度都是 O(1)。并且 获取某个节点的前驱/后继节点的复杂度也是 O(1)。
不过 链表 有个很大的缺陷就是 每个节点间的内存在物理上是不连续的,这就导致链表 无法很好的利用 CPU 缓存,因为 CPU 向内存读取数据时,都是一次性读取连续的内存空间到缓存中。
而且链表除了保存数据外,还使用了额外的空间保存其他信息,比如前驱/后继节点,内存开销比较大。
基于以上缺点,Redis 3.0 的 List 在数据量较少时采用了压缩列表作为底层实现,而又因为压缩列表存在性能问题(后续文章会讲解),在最新版本中使了 quicklist 来实现。
4. 压缩列表
前面说到双向链表最大的缺陷就是物理上内存空间不连续,而且每个节点都会消耗额外的空间保存头信息。那么压缩列表的实现,就很好的解决了它的问题。
压缩列表是一种紧凑型的数据结构,在物理上内存空间是连续的,而且 不需要为每个元素都保存额外信息,Redis 还针对不同的数据大小,设计了多套编码规则,以此来达到 占用更小内存 的效果。
当 List、Hash、zSet 保存的元素数量较少、元素值不大 的情况下,会使用 压缩列表 来实现。为什么需要上述两个条件?这跟压缩列表的缺陷有关,我们后续说明。
4.1 压缩列表结构
压缩列表跟数组类似,使用一块连续的内存保存数据,只不过在数组的基础上,新增了一些字段以方便对其的操作:
- zlbytes:整个压缩列表 占用内存的字节数;
- zltail:压缩列表尾节点距离起始地址的字节数,即 尾节点的偏移量,以方便获取尾节点;
- zllen:压缩列表的 节点数;
- entry:压缩列表中的节点,节点中保存实际的数据;
- zlend:压缩列表的 结束标志,是一个固定值 0xFF。
而对于保存数据的节点 entry,包含三个属性:
- prev_entry_len:前节点的长度,以找到上一个节点,方便 从后往前遍历;
- encoding:当前节点 value 的 数据类型,还可以知道 当前节点的长度,以找到下一个节点,类型有字符串和整数;
- data:当前节点的 实际数据。
压缩列表的整体结构如下:

接下来详细讲解 entry,其 prevlen 的大小取决与前节点的大小:
- 若 前节点的长度小于 254 字节,则 prevlen 使用 1 字节 来保存该长度值;
- 反之,prevlen 使用 5 字节 来保存前节点的长度值。
其 encoding 编码的类型和占用的大小,取决于保存数据的类型 (字符串或整数) 和大小 (字符串的长度):
- 若保存的数据是 整数,则 encoding 编码方式有多种,但都只占用 1 字节;
- 若保存的数据是 字符串,则根据 字符串的长度大小,encoding 有不同的编码方式,占用的空间大小也不相同,分别由 1/2/5 字节。
详细的编码规则如下,content 即 data:

encoding 编码的前两位表示数据类型,对于字符串类型来说,除了前两位外的剩余位就表示字符串的实际长度。
4.2 压缩列表缺陷
压缩列表有一个很大的缺陷,就是 因为 prevlen 变大导致的连锁更新。
通过前面我们知道,prevlen 空间大小取决于前一个节点所占用的空间大小,那么当压缩列表中的 entry 都占用了接近 254 字节的空间时,此时 prevlen 使用 1 字节刚刚好足够保存。但突然 将一个大于 253 的 entry 插入到头节点时,那么 prevlen 就要从 1 字节扩大到 5 字节了,扩大后,后面的 prevlen 也要继续扩大,就会导致连锁更新了。
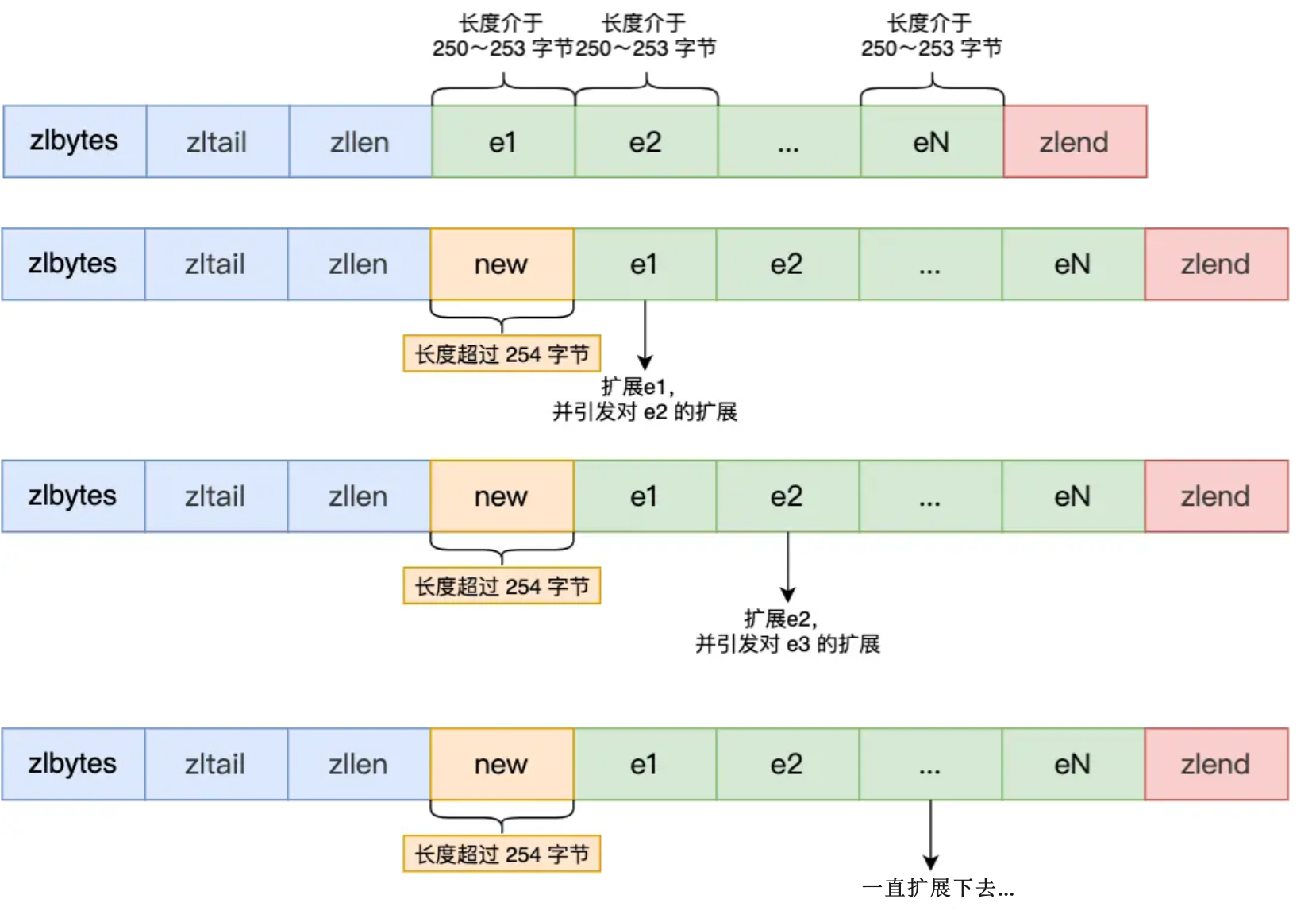
这种连锁更新导致的 内存扩展需要重新分配内存,多次重新分配内存无疑会消耗很大的性能,从而导致压缩列表的 访问性能下降。
所以刚开始说当 List、Hash、zSet 保存的元素数量较少、元素值不大 的情况下,会使用 压缩列表 来实现。因为元素较少时,即使发生了连锁更新,影响也不算太大。
不过 Redis 5.0 引入的 listpack 解决了这种连锁更新的问题。
5. 哈希表
Redis 的哈希表与普通哈希表类似,只是多了几个属性,额外又封装了一层,方便操作。
Redis 哈希表的结构定义如下:
typedef struct dictht {
dictEntry **table; //哈希表数组
unsigned long size; //哈希表大小
unsigned long sizemask; //哈希表大小掩码,用于计算索引值
unsigned long used; //该哈希表已有的节点数量
} dictht;
其中,哈希表 table 由一个 哈希表节点数组 构成,其结构如下:
typedef struct dictEntry {
void *key; //键值对中的键
//键值对中的值
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; //指向下一个哈希表节点,形成链表
} dictEntry;
可以发现,dictEntry 的值是一个联合体,所以这个值是其中的某一种,这样当保存的数据是 整数或浮点数 时,就可以 直接将数据嵌入到结构体中,节省了指针的空间。若是其他数据类型时,则需要 void 指针指向实际的数据。
在解决 哈希冲突 问题时,Redis 采用了比较简单的 链式哈希,next 指针的作用即使如此。
一个哈希表结构例子如下所示:

我们知道,在使用链式哈希来解决哈希冲突时,有一个问题就是 当链表长度过长时,会导致哈希表的 查询时间复杂度从 O(1) 将为 O(n)。要解决这个问题,就需要进行 rehash 对哈希表进行扩容。
哈希表数据类型的 rehash 与全局哈希表的是一样的,都是使用 渐进式 rehash,具体内容可以看 kv 数据库如何实现。Redis 在实际使用哈希表时,会定义一个 dict 结构,里面包含了两个哈希表:
typedef struct dict {
//…
dictht ht[2]; //两个Hash表,交替使用,用于rehash操作
//…
} dict;
rehash 的触发条件跟 负载因子 (Load Factor) 有关,它的计算公式为:
- 负载因子 = 哈希表已存储节点数 / 哈希表大小
Redis 哈希表触发 Redis 的条件有两个:
- 当负载因子大于等于 1,并且没有进行 RDB 或 AOF 重写(bgsave / bgrewriteaof 命令)时,就会进行 rehash;
- 当负载因为大于等于 5 将强制进行 rehash,因为此时哈希冲突已经很严重了。
6. 整数集合
当 Set 数据类型 只包含整数元素,并且数量不多时,就采用 整数集合 作为底层实现,否则采用哈希表。
整数集合在物理上是一块连续的内存空间,结构如下:
typedef struct intset {
uint32_t encoding; //编码方式
uint32_t length; //集合包含的元素数量
int8_t contents[]; //保存元素的数组
} intset;
此处需要注意,contents 的类型并不是 int8,而是由 encoding 决定。
所以,当新插入元素的类型比 contents 数组原有类型大时(比如向 uint16_t 的 contents 中插入一个 uint32_t 类型的数据),就会先进行 contents 数组的 内存升级 (扩容),全部扩容为新插入元素类型大小后,再将旧元素放置到新的位置,才能将新元素插入。
这样做的好处无疑还是 节省内存空间,需要存储多大数据类型的值,才分配多大的内存。
不过整数集合 不支持降级操作,升级后就算删除了类型较大的元素,这个整数集合依旧是原来的类型大小。
7. 跳表
zSet 的底层实现之一是跳表,它是一种基于链表的多层结构,优化了查询时的时间复杂度,为 O(logN)。
并且 zSet 的 ZSCORE 命令支持通过 key 获取指定 member 的 score(复杂度为 O(1)),也能通过 ZRANGEBYSCORE 按照 score 获取指定范围的 member(复杂度为 O(logN))。
其实这与 zSet 的底层数据结构有关,翻开 zSet 的源码,可以看到它是由 dict 哈希表和 zsl 跳表 组合实现的:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
所以,我们在往 zSet 中插入/更新数据时,Redis 会分别在跳表和哈希表中都进行插入/更新。
在哈希表中,key 就是 member,value 是一个指针,指向该 member 在跳表中的 score,所以可以快速定位到一个 member 的 score。
在 Redis 中,跳表节点的定义如下:
typedef struct zskiplistNode {
// Sorted Set中的元素
sds ele;
// 元素权重值
double score;
// 后向指针
struct zskiplistNode *backward;
// 节点的level数组,保存每层上的前向指针和跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
可以看到,除了保存数据、score 等信息之外,还有一个 level 数组,里面记录了该节点的前向指针(用于倒序查询),以及跨度 span,span 的值是两节点之间的节点数 + 1,由于 跳表是按序排列的,所以可以 通过 span 来获取某元素在集合中的排名(即 ZRANK 命令)。
下面再来看看跳表结构体的定义:
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
跳表结构体中定义了头尾指针、跳表的长度和层数,这样在查询时直接从头/尾指针开始访问即可。
完整的跳表结构如下:

可以发现,在查询时,从最顶层根据跳表的特性往下层寻找,当上下相邻层的结点数之比为 1:2 时,就把链表的 O(N) 复杂度降到了 O(logN),类似二分查找。
7.1 如何维持上下相邻层的结点数之比为 1:2
如果要强行维持,那么在势必会影响插入/删除性能,因为涉及到其他节点层数的调整。
来看看 Redis 是怎么设计的,其中 zslRandomLevel() 是用来生成节点的层数的:
#define ZSKIPLIST_MAXLEVEL 64 // 最大层数为64
#define ZSKIPLIST_P 0.25 // 随机数的值为0.25
int zslRandomLevel(void) {
// 初始化层为1
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
可以发现 Redis 是 随机生成每一个节点的层数,具体来说:
- 层数先初始化为 1;
- 然后 生成一个随机数,如果小于 ZSKIPLIST_P(节点增加一层的概率,值为 0.25),那么层数就 +1;
- 所以 节点的层数每增加一层的概率不超过 25%,从概率学的角度来说,这能保证上下相邻层的结点数之比约为 1:2。
这样一来,当向跳表中插入一个节点时,就只需要修改前后结点的指针指向即可。
7.2 跳表的插入过程
以下面这个简约版的跳表来演示插入一个分值为 9.5 的节点(注意后向指针未画出):

1、先找到待插入节点的后向节点,过程中记录头节点到后向节点的跨度。
注意后向指指针的方向往后,不是后继节点,前向同理,不要和链表的前驱后继节点搞混了。
- 记录跨度是为了在插入新节点后,后向节点的跨度发生了改变,而且要计算新节点的跨度;
- 注意:后向节点和跨度是保存在一个数组中的,因为每层的后向节点和跨度都不同,数组下标就是层数;
- 至于如何查找的,后面在跳表的查询过程时讲解。
2、随机生成新节点的层数。
- 上面已讲解如何随机生成节点层数。
3、插入新节点。
假设上面生成的随机层数为 2,那么分值为 9.5 的元素插入后,跳表应该如下:

要实现这个效果,需要两步:
- 找到新节点在 每一层的后向节点(第一步已经找到了),即对于 lv0 应该找到节点 9,对于 lv1 应该找到节点 8;
- 将新节点插入到 每一层 的后向节点之后,然后新节点的前向指针指向其后向节点原来的前向节点(跟普通链表的插入一样)。
注意每一层都需要操作,新节点在每层的后向节点在第一步中都已经存储在一个数组中了。
4、计算每一层的跨度 span。
插入一个新节点后,该新节点的跨度和其在每一层的后向节点的跨度都需要计算;
首先来看最底层,最底层的跨度其实都是 1,因为最底层压根就没有跳,所以不用计算;
对于 lv1 层,要想办法确定节点 8 到节点 9.5 和节点 9.5 到 节点 12 之间的距离。实际上这两个只确定一个就可以,因为 这两个距离之和就是原来 lv1 层节点 8 的 span 再 +1(插入了新节点)。
来看看节点 8 到节点 9.5 之间的距离怎么算,其实可以转换为 lv1 层节点 8 到 lv0 层节点 9 之间的距离 + 1(因为对于 lv0 层来说跨度都为 1),即下面这段:

那这段又怎么算呢?可以把它转换为下面两段距离的差,这两段的值在第一步统计后向节点的跨度时都记录下来了;

注意:对于每一层的跨度都需要更新,每层的原始跨度在第一步时已经统计出来了,存放在一个数组中。
5、设置后向指针,更新跳表总节点数和最高层数。
- 针对每一层都调整完成后,要将新节点的后向指针指向它的后向节点,新节点的前向节点的 后向指针 再指向新节点,后向指针不在 level 数组中,不用每层都设置;
- 最后要更新最外层的跳表结构,即 总结点数 (length) 和层数 (level)(如果最高层数发生了变化)。
7.3 跳表的查询过程
在查询一个跳表时,会从最高层开始,逐层往下查询,查询过程中的 判断依据是节点中 SDS 类型的元素大小及它的权重:
当前节点权重小于待查寻节点的权重时,访问 该层的下一个节点;
当前节点权重等于待查寻节点的权重,并且 当前节点的 SDS 类型小于待查寻数据时,访问 该层的下一个节点;
因为权重相同的节点,会按照 SDS 类型的大小进行排序。
若 上述条件都不满足,或 下一个节点为 NULL 时,访问下一层,沿着下一层继续查找。
例如,从下面的 3 层跳表中,查找「元素 abcd,权重为 4」的节点:

过程如下:
- 从最高层的头节点开始,L2 指向了「元素:abc,权重:3」节点,该节点权重小于待查寻节点,所以访问该层的下一个节点,但下一个节点为 NULL,因此访问下一层 L1;
- 「元素:abc,权重:3」节点的 L1 层下一个节点指向了「元素:abcde,权重:4」节点,权重比较相同,但当前节点 SDS 类型(abcde)大于待查寻节点 SDS 类型(abcd),因此还要继续访问下一层 L0;
- 「元素:abc,权重:3」节点的 L0 层下一个节点指向了「元素:abcd,权重:4」节点,查询结束。
8. quicklist
前面说过,List 数据结构的底层实现之前是双向链表或压缩列表,但是由于 压缩列表存在连锁更新的问题,所以 Redis 3.2 时,改用了 quicklist 作为 List 的底层实现。
quicklist 其实就是 双向链表 + 压缩列表 的组合,它就是一个链表,链表中的节点元素又是一个压缩列表。它通过 控制压缩列表的大小或数量 来规避连锁更新的问题,因为在元素较少时,连锁更新带来的影响也不大。
quicklist 的结构如下:
typedef struct quicklist {
quicklistNode *head; //quicklist的链表头
quicklistNode *tail; //quicklist的链表尾
unsigned long count; //所有压缩列表中的总元素个数
unsigned long len; //quicklistNodes的个数
//......
} quicklist;
quicklistNode 结构:
typedef struct quicklistNode {
struct quicklistNode *prev; //前一个quicklistNode
struct quicklistNode *next; //后一个quicklistNode
unsigned char *zl; //quicklistNode指向的压缩列表
unsigned int sz; //压缩列表的的字节大小
unsigned int count : 16; //ziplist中的元素个数
//......
} quicklistNode;
可以发现,quicklistNode 中有 prev 和 next 指针,其实就是一个双向链表,而 *zl 指针指向一个压缩列表,规定了其中的元素个数为 16 个。
quicklist 结构示意图如下:

在插入新元素时,会先往压缩列表中插入,压缩列表满后,才会新建一个 quicklistNode,然后往新的压缩列表中插入。
通过控制压缩列表的数量,规避了连锁更新带来的性能问题,但是 并没有完全解决该问题,因为连锁更新问题的根源在于压缩列表的 prevlen 属性的设计。不过在 Redis 5.0 中新设计的 listpack 彻底避免了连锁更新的问题。
9. listpack
Redis 5.0 新引入的 listpack 去掉了 prevlen 属性,就是为了代替压缩列表,彻底避免连锁更新的问题。
listpack 借鉴了压缩列表的优势,只不过 把 prevlen 属性改成了当前节点的长度:

其中:
encoding 还是元素的编码类型,根据不同大小的整数和字符串进行不同的编码,以节省内存;
data 存放实际的节点数据;
len 就是当前节点 encoding + data 的长度。
去掉 prevlen 属性,那还能从后往前遍历吗?
也是可以的,listpack 有一个 lpPrev 函数,就是返回前一个元素的起始地址:
/* If 'p' points to an element of the listpack, calling lpPrev() will return
* the pointer to the preivous element (the one on the left), or NULL if 'p'
* already pointed to the first element of the listpack. */
unsigned char *lpPrev(unsigned char *lp, unsigned char *p) {
if (p-lp == LP_HDR_SIZE) return NULL;
p--; /* Seek the first backlen byte of the last element. */
uint64_t prevlen = lpDecodeBacklen(p);
prevlen += lpEncodeBacklen(NULL,prevlen);
return p-prevlen+1; /* Seek the first byte of the previous entry. */
}
其中 lpDecodeBacklen 函数是具体的算法,就是从当前节点往后查找前一个元素的长度,具体算法如下:
/* Decode the backlen and returns it. If the encoding looks invalid (more than
* 5 bytes are used), UINT64_MAX is returned to report the problem. */
uint64_t lpDecodeBacklen(unsigned char *p) {
uint64_t val = 0; // 用于存储解码后的长度值
uint64_t shift = 0; // 用于跟踪解码过程中的位移量
do {
val |= (uint64_t)(p[0] & 127) << shift; // 将字节中的低 7 位存储到 val 中,位移量由 shift 控制
if (!(p[0] & 128)) break; // 如果字节的最高位不为 1,则表示该字节是最后一个字节,结束解码过程
shift += 7; // 更新位移量,准备解码下一个字节
p--; // 后退一个字节,继续解码后一个字节
if (shift > 28) return UINT64_MAX; // 如果位移量超过了28位,表示解码的长度超过了 ListPack 所支持的范围,返回 UINT64_MAX 表示出现问题
} while(1); // 一直循环直到解码完成或出现问题
return val; // 返回解码后的长度值
}
算法的底层逻辑就不过多研究了,So difficult!
10. 总结
最后再来回顾下 Redis 中各种数据类型对应的底层结构:
11. 参考文章
- 小林 coding
- 《Redis 设计与实现》
- Redis 跳跃表图解&插入详述