MQ 常见问题合集
本文内容
为什么要使用 MQ?
MQ 主要有下面几个作用,这也是为什么要使用 MQ 的原因:
- 异步处理:当业务需要处理的逻辑非常多的时候,可以 把一些用户不关心的、耗时的逻辑丢到 MQ 中做异步处理,从而尽快将结果返回给用户;
- 业务解耦:在我的抽奖系统中,可以将抽奖和发奖解耦开来,用户抽奖后,直接返回奖品信息,具体的奖品类型是什么,应该怎么发放,后续由 MQ 去执行,最后将结果持久化到 DB 即可;
- 流量削峰:当并发量过大时,可以利用 MQ 进行缓解。在我的校园社区项目中,发送系统通知就是用 MQ 来削峰的,避免在点赞、评论、私信消息过多时,影响系统性能。
如何设计一个 MQ?
要设计一个消息队列,可以从一下几个方面来考虑:
- 保证消息的可靠:可以设置 ACK 机制、消息的超时重传 等,避免消息丢失;
- 消息的持久化机制:为了防止进程挂掉后消息的丢失,需要做消息的持久化,这个持久化最好是采用 顺序写,提高持久化性能;
- 保证 MQ 的高可用:当一个 MQ 崩溃时,要保证整个 MQ 是可用的,所以需要使用 多副本机制 来保证;
- 支持 MQ 的伸缩:MQ 需要具备随时扩容的能力,以保证在消息量激增时及时提高吞吐量和容量。所以需要设计一个 分布式的 MQ;
- 高性能:要设计一个高性能的 MQ,可以参考 Kafka 的设计架构,一个 broker 下可以设置多个 topic,一个 topic 又有多个 partition,多个 concumer 可以组成一个消费者组,一个分区由一个组内的消费者进行消费。通过这样设计,一个 topic 中的消息可以在多个 partition 中,由多个消费者并行消费,大大增加了吞吐量。
参考 Kafka 的基础架构:

消息积压问题
出现 消息积压问题 主要是由于 消费者出现故障、消费者执行了耗时的操作(比如操作 DB 遇到了性能瓶颈)、消费速度跟不上生产速度 等原因造成的。
一般消息积压问题是从消费者层面来解决,因为生产者对接的是上游业务,是不能轻易改动的。常见的 解决方案 有如下:
- 扩容增加消费速度,增加节点数量或将 Partition 和 Consumer 的数量增加到原来的 X 倍(取决于具体情况),让积压的消息尽快消费完毕,后续在恢复成原来的;
- 消息先抛后补,当积压严重时,MQ 都快打满了,为了保证系统的可用性,需要进行消息抛弃(新建消费者来获取消息丢弃),后续在流量低的时候再补回来;
- 合并消费消息,如果有些消息可以合并消费的,可以丢到一个消息中进行消费,以提高消费速度(减少网络传输、减少 IO 操作等)。
顺序消费问题
保证局部有序—同 partition 下的消息
对于需要顺序消费的消息,可以指定一个 key,对于相同的 key,Kafka 能保证它们被分发到同一个 partition 中。
为什么会乱序:
- 对于 Kafka 来说,同 partition 下的消息消费是可以保证顺序消费的,但为了增加吞吐量,消费者一般都是使用多线程进行消费,这就会导致乱序。
解决方案:
- 既然是多线程消费导致乱序,而让一个线程只处理一个消费者吞吐量又太低,那么可以加一个 中间层——内存队列。一个消费者对应多个内存队列,每个线程只消费一个内存队列,将消费者中具有相同 key 的数据放到同一个内存队列进行消费,以此来保证有序。
这样既可以保证并发消费消息,也能保证有序。
示意图:
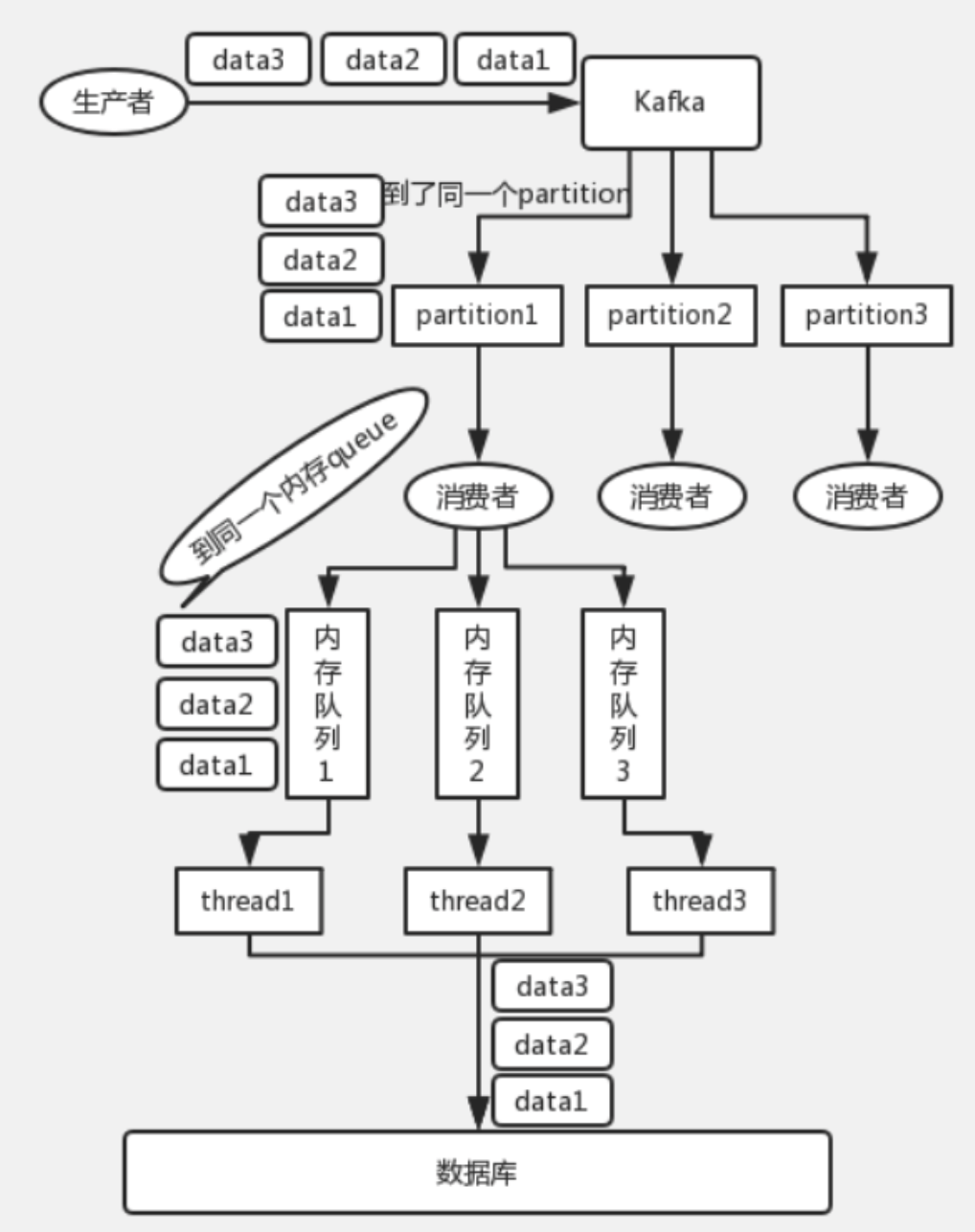
保证全局有序—同 topic 下的消息
为什么会乱序:
- 生产者生产的消息会被分发到不同的 partition,而 不同的 partition 由不同的消费者进行消费,不同的消费者又有多个线程进行处理,所以如果在不指定一个 key 的情况下,很容易就会发生乱序。
解决方案:
- 在这种情况下,就只能 将 topic-partition-consumer-线程都设置成一比一的对应关系,才能保证消息的有序性。
如何解决幂等问题?
具体看 如何保证消息幂等。
高可用性—多副本机制
拿 Kafka 举例:Kafka 提供的 多副本机制 主要用来提高 MQ 集群的 高可用性,这也是它能成为一个天然分布式 MQ 的重要原因。
在 Kafka 中,一个 topic 中的数据可以分发到多个 partition 中,这些 partition 可以分布到不同的 broker 上,此时还不能保证高可用,因为 一个 broker 宕机会导致这个 partition 的消息不可用。
为了避免这种情况,Kafka 提出了 多副本机制,即 broker 上的每个 partition 在其他 broker 中会形成多个副本,Kafka 会均匀的将这些副本分散到不同的 broker 中,以提高容错性。
既然有了副本,就会涉及到 数据一致性问题,Kafka 为了降低复杂度,采用了 leader-follower 模式,在实际生产和消费时,都是和 leader 进行交互,然后 leader 会同步消息给 follower。当 leader 不可用时,才会轮到 follower 上场(在其中选出一个 leader)。
leader 读写细节:
写数据时,生产者只向 leader 写,leader 会将数据写入磁盘,其他 follower 会主动 pull 数据。follower 完成数据同步后,会发送 ack 给 leader,leader 接收到所有 follower 的 ack 后,才会返回写成功的消息给生产者。
这是 ISR(In-Sync Replicas)模式,可用性更高;如果你想让延迟更低,可以损失一点可用性,那么可以选择非 ISR(Out-of-Sync Replicas)模式,此模式不会等到 follower 都确认后才返回写成功。
读数据时,消费者也只向 leader 读,同样地,只有当这条消息已经被所有 follower 同步成功后,才会被消费者读到。