熔断 - 如何防止抖动
本文内容
前言
在微服务架构中,系统的 可用性 是非常重要的,为了避免高并发下服务的崩溃,通常会使用 熔断、限流、降级 等措施。本文就先来讲解服务熔断是什么,它是如何提高系统的可用性的,服务出现抖动了怎么办?
1. 什么是服务熔断?
熔断,指的是 当微服务本身出现问题时,熔断器就会拒绝新的请求,直到微服务恢复正常。

可以发现,客户端直接收到了请求错误的响应,在客户端看来,该服务就是不可用的,那么为什么熔断器还能提高系统的可用性呢?
回到熔断器工作的前提条件,在服务本身出现问题的时候,它才会工作。可以想象一下,如果某服务器因为自身压力过大,马上就快宕机了,这时如果没有熔断器,继续接收新的请求,那么这个新请求可能就是压死骆驼的最后一根稻草,导致服务彻底的不可用。
而使用了熔断器,在服务器压力过大时,可以帮助服务器拒绝请求,从而给时间让服务器恢复,等服务器恢复正常时,再接收请求。并且,上游服务可以在接收到熔断信息后,进行兜底方案的处理。
那么熔断器在设计的时候就需要关注两点:
- 怎么判断微服务出现了问题?
- 怎么知道微服务恢复了?
2. 判断服务健康状态
要判断服务是否出现了问题,其实有点像在 负载均衡 中讲的动态算法。都是要 根据业务的一些指标,来反映服务器的健康程度,例如响应时间、错误率等。
但是不管选择什么指标,都需要考虑两个问题:
- 阈值如何选择?
- 超过阈值后,直接熔断还是过一段时间?
2.1 阈值如何选择?
加入我们选择把响应时间作为指标,那么响应时间超过多少才触发熔断呢?这就是阈值的选择。
其实没啥固定的选择,需要 根据业务来决定,比如业务对响应时间要求在 1s 内完成,那么阈值就可以设置在 1s,或者高一点,留点容错的余地。

2.2 超过阈值后何时熔断?
当选定的指标超过阈值后,是立即熔断,还是过一段时间再熔断呢?
如果 立即熔断,那么就 无法规避偶发性的增长,比如只是因为网络波动导致的暂时响应过慢,如下图所示。

所以一般都是 在选定的指标超过一段时间后才触发熔断,那么这个一段时间到底是多长呢?
- 如果时间过短,服务器还未恢复到位,可能会导致频繁触发熔断;
- 而如果时间过长,又会出现该触发熔断时没触发,导致服务器直接崩溃。
这个就需要根据个人经验来了,比如 30s,1min。
3. 判断服务恢复正常
第二个要考虑的就是 服务熔断后的恢复,也就是服务器恢复正常后,就要退出熔断状态,继续提供服务。
所以 触发了熔断后,还需要检测服务是否已经恢复正常了。
这方面大多数微服务框架都做得比较差,大多都是触发熔断后,一段时间就退出熔断了(比如 1min),继续处理新请求了。
这里就涉及前面提到了 抖动问题 了,即 服务在正常 - 熔断之间频繁切换。
比如在高并发场景下,服务在触发熔断后,一分钟后并发依然很高,如果这时候直接恢复,流量打过来又会导致熔断出发:

想解决这个问题,就需要 在恢复时控制流量,比如按照 10%、20%、30% ...... 逐步递增,而不是直接恢复 100% 的流量,就像灰度发布一样。
这可以通过熔断器来实现:

但这种做法有个 缺点,因为是靠熔断器来处理请求的,所以 还是会拒绝一部分请求,比如刚开始只放 10% 请求时,就会有 90% 的请求返回失败的响应,这显然是不优雅的做法。
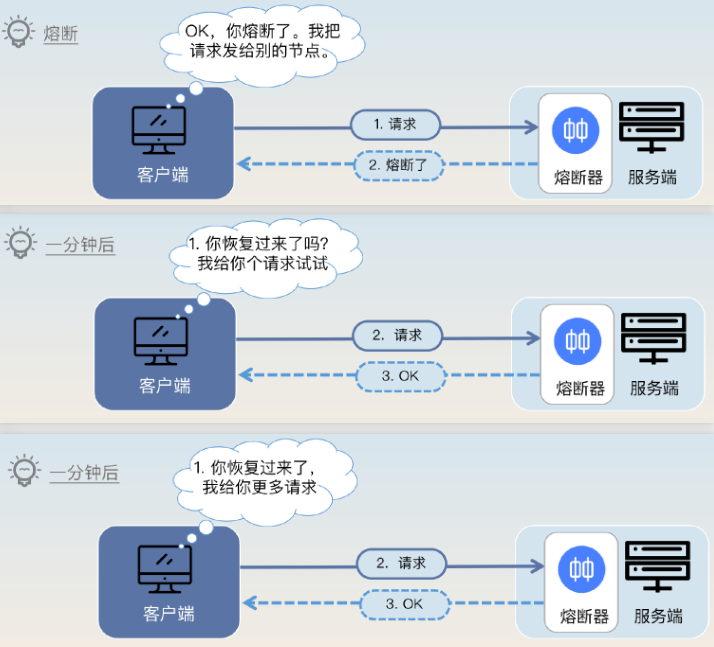
其实,解决办法很简单,让客户端来控制这个流量即可。可以在熔断触发后,客户端就直接不再请求该节点,换一个节点,等恢复后,客户端再逐步对这个节点放开流量。

4. 如何让客户端控制熔断恢复后的请求流量?
我在 负载均衡 里面讲到过可以 根据响应结果来动态调整负载均衡的策略,在这里也可以采用这种思想。
具体来说,在触发了熔断后,客户端在做负载均衡时,就可以将该节点暂时移出可用列表。经过一段时间后,客户端再尝试逐步访问该节点,如果响应正常,则加大流量即可,否则就再等一段时间。
过程如下:
- 客户端收到熔断错误时,暂时把这个节点移出可用节点列表,这样可以保证后续的所有新请求都不会打到该节点;
- 客户端等待一段时间后,再将该节点移进可用列表,逐步放开流量:
- 如果服务端能正常处理新请求,那客户端就可以加大流量;
- 如果服务端还是返回熔断错误,那再次将该节点移出可用列表。
- 如此循环,直到服务端完全恢复即可。
5. 总结
本文介绍了保证微服务可靠的重要措施之一,熔断,即 当微服务本身出现问题时,触发熔断可以让该服务暂时拒绝请求,以给服务器恢复的机会,恢复完成后即可重新接收请求。
熔断的两个核心点在于什么时候进行熔断,和什么时候恢复正常?也就是 判断服务是否健康 和 判断服务是否已恢复正常。
在判断服务是否健康时,一般可以使用响应时间、错误率等指标,这里需要根据业务来设定阈值。但也要注意考虑偶发性问题,并不是超过阈值就立马触发熔断,而是持续一段时间后如果服务还是不可用,再触发熔断机制。
而在判断服务是否已经恢复正常时,切忌直接过段时间直接恢复全部流量,而是要逐步放开流量,避免又触发熔断,导致抖动问题。
另外一种高级的做法是,在客户端结合负载均衡,控制对该节点的访问流量。